[디자인패턴] 팩토리 메소드 패턴 with python
Head First Design Pattern 에 소개되는 예제를 파이썬으로 구현하였습니다.
Head First Design Pattern 에 소개되는 예제를 파이썬으로 구현하였습니다.
Head First Design Pattern 에 소개되는 예제를 파이썬으로 구현하였습니다.
Head First Design Pattern 에 소개되는 예제를 파이썬으로 구현하였습니다.
Head First Design Pattern 에 소개되는 예제를 파이썬으로 구현하였습니다.
앱이 여러 개 있을 때, URL에 따라 앱 별로 요청을 전달하는 방법에 대해 살펴보자.
templatetags를 사용하여 static 파일이 캐시되는 이슈를 해결합니다.
장고의 제네릭 뷰를 살펴보고 예제를 작성해 보자.
장고에서 요청을 받고 응답하기까지의 프로세스를 살펴보자.
오차역전파를 사용한 학습도 손실함수를 최소화하는 가중치를 찾는 것을 목표로합니다. 다만, 역전파는 가중치를 구함에 있어 연쇄법칙에 기반한 국소적 미분을 활용합니다. 순전파와 비교했을 때 훨씬 빠른 시간 안에 효울적으로 계산한다는 장점이 있습니다. 이번에는 역전파법을 사용하여 모델 학습을 진행해 보겠습니다.
먼저, 라이브러리와 공통함수를 읽어옵니다.
1 | #install.packages("dslabs") |
1개의 은닉층을 갖는 네트워크를 생성합니다. 네트워크는 순전파와 동일합니다.
1 | TwoLayerNet <- function(input_size, hidden_size, output_size, weight_init_std = 0.01) { |
데이터를 불러와 트레이닝셋과 테스트셋으로 분리하는 init()함수를 생성합니다.
1 | init <- function(){ |
앞서 역전파에서는 국소적 미분을 사용한다고 했습니다. 순전파와 반대방향으로 국소적 미분을 곱하여 이전 노드들에 값을 전달하는 것인데, 국소적 미분은 순전파 때의 미분을 구한다는 뜻입니다. 다시 말해, 순전파 때의 미분 값을 구해 다음 노드에 전달하는 함수가 필요합니다.
다음 코드는 순전파 때와 마찬가지로 입력신호와 가중치를 계산하고 Relu함수를 거쳐 다음 노드로 전달합니다.
1 | forward <- function(x){ |
역전파도 마찬가지로 손실함수를 계산합니다.
1 | loss <- function(model.forward, x, t){ |
순전파와 달리 마지막 노드에서부터 거꾸로 계산해 기울기를 구합니다.
1 | gradient <- function(model.forward, x, t) { |
다음은 학습을 실제로 진행하는 코드입니다.
1 | train_model <- function(batch_size, iters_num, learning_rate, debug=FALSE){ |
train_model()함수 중간에 sg.update()함수는 경사하강법으로 변경된 가중치를 업데이트하는 역할을 합니다.
코드는 아래와 같습니다.
1 | sgd.update <- function(network, grads, lr = 0.01){ |
이제 모든 준비를 마쳤습니다. 네트워크를 생성한 후 모델을 학습시켜봅니다.
1 | network <<- TwoLayerNet(input_size = 784, hidden_size = 50, output_size = 10) |
위 코드를 실행시키고 3분 정도 지나면 아래와 같은 출력화면이 나올 것입니다. 한 행의 첫 번째 숫자는 훈련데이터 셋에 대한 정확도, 두 번째 숫자는 테스트 셋에 대한 정확도를 나타냅니다. 그리고 하나의 행은 1에폭(epoch)을 의미합니다. 에폭을 진행할수록 정확도가 높아지는 것을 확인할 수 있습니다!
1 | [1] 0.9048 0.9059 |
먼저, 학습할 네트워크를 만듭니다. W1,W2는 각 층별 가중치이며 b1,b2는 편향 값을 의미합니다.
1 | TwoLayerNet <- function(input_size, hidden_size, output_size, weight_init_std = 0.01) { |
TwoLayerNet 네트워크는 아래와 같이 은닉층을 1개 갖습니다.
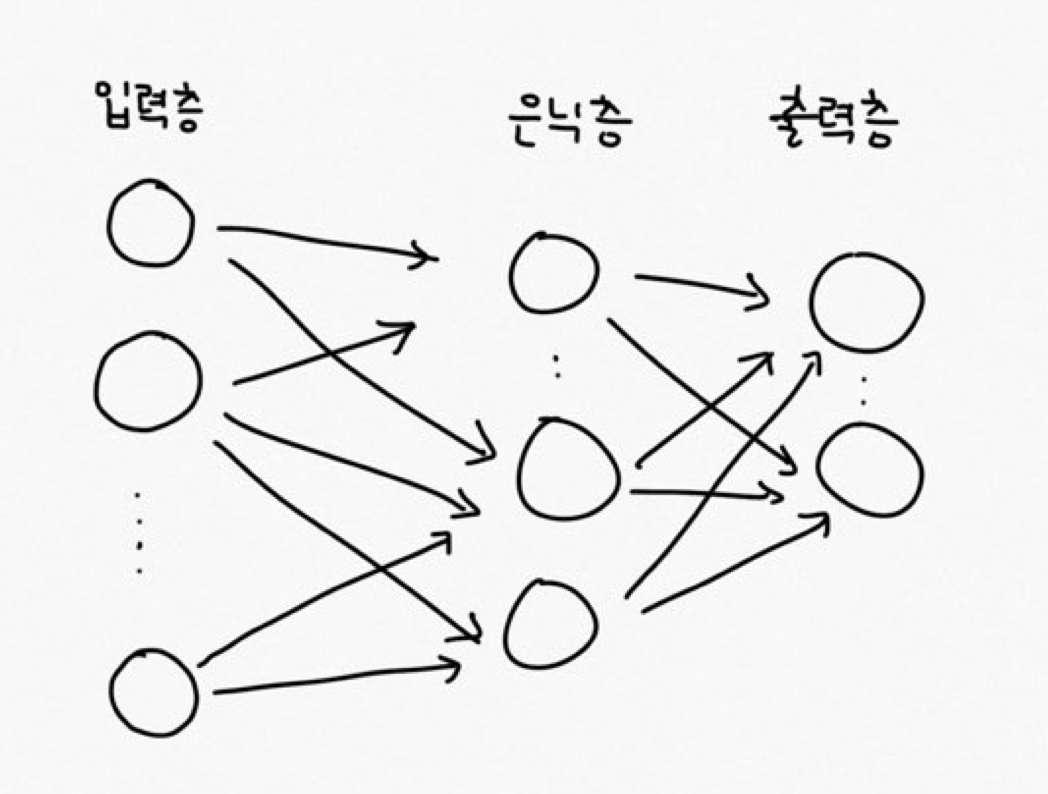
입력층에서 input_size 개수만큼의 노드를 갖고 은닉층에서는 hidden_size 개수만큼의 노드, 출력층에서는 output_size만큼의 노드를 갖습니다. W1과 b1은 입력층에서 은닉층으로 갈 때의 가중치와 편향이며 W2와 b2는 은닉층에서 출력층으로 갈 때 사용하는 가중치와 편향입니다. 그리고 weight_init_std는 가중치 초기값이 큰 값이 되는 것을 방지하는 파라미터입니다.
다음으로, 데이터를 불러오고 트레이닝 셋과 테스트 셋으로 분류합니다. 데이터는 MNIST 라이브러리의 손글씨 이미지입니다. R에서는 dslabs를 임포트합니다.
1 | library(dslabs) |
손실함수는 교차엔트로피오차 함수를 사용합니다. 교차엔트로피오차 함수는 아래와 같이 구현합니다.
1 | model.forward <- function(x){ |
기본 교차엔트로피 함수식에 delta값을 추가하였는데, 이는 log0이 되면 -Inf가 되는 문제를 방지하기 위해서 입니다.
다음으로 경사하강법은 손실함수 값을 최소화 시키기 위해 사용합니다.
1 | numerical_gradient_W <- function(f,x,t,weight){ |
마지막으로 학습시키는 함수입니다.
1 | train_model <- function(batch_size, iters_num, learning_rate, debug=FALSE){ |
train_model()함수 중간에 sg.update()함수는 경사하강법으로 변경된 가중치를 업데이트하는 역할을 합니다.
코드는 아래와 같습니다.
1 | sgd.update <- function(network, grads, lr = 0.01){ |
이제 모든 준비를 마쳤습니다. 네트워크를 생성한 후 모델을 학습시켜봅니다.
1 | network <<- TwoLayerNet(input_size = 784, hidden_size = 50, output_size = 10) |